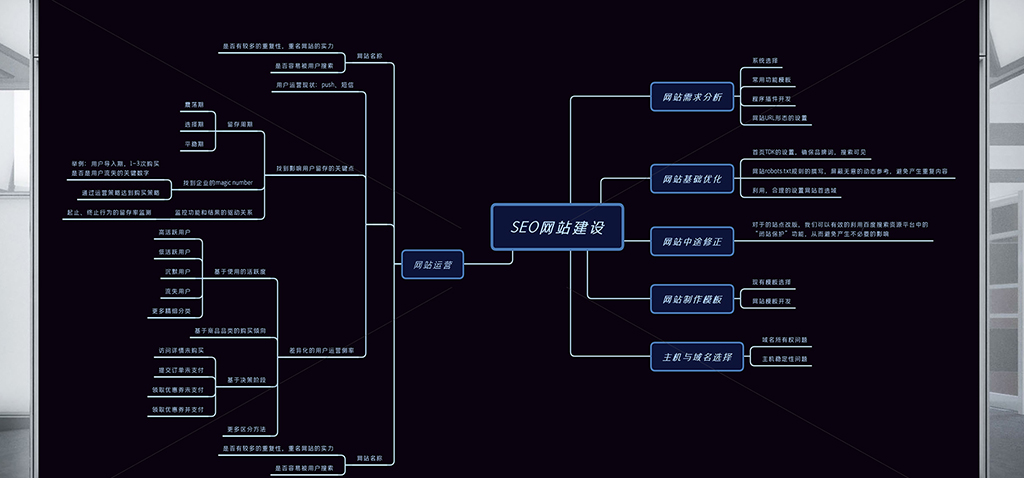
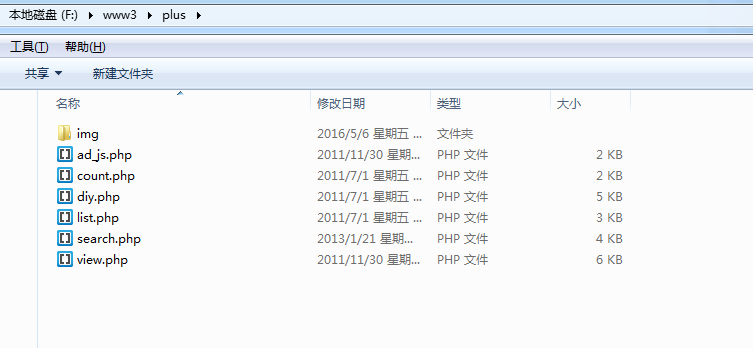
目标:在Linux服务器上部署平台管理系统,实现外网访问。一、Linux简介1.Linux系统概述

由左左在2020年10月31日上张贴在昨天的课程中,我们解读了用户的搜索意图,并且介绍了一个比较经典的分析模型——消费者旅程(ConsumerJourney)。今天的课程我们会在昨天的基础上进一步深挖,来学习下SEO关键词研究的理论部分。在正式开始讲课之前,我想先聊聊SEO新手在做关键词研究的时候比较容易犯的错误。关键词研究的常见错误操作我发现的最...
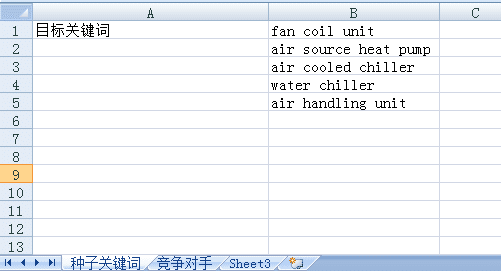
由左左在2020年11月4日上张贴上一节课我们已经介绍过关键词研究的相关理论,今天开始,我们正式进入实操。为了节省时间,我们不会在实操课程中重复介绍概念,如果有术语不明白的,请自己返回关键词研究理论课程去温习,而且我们以后的实操课都会采用这个方式进行。我们在理论课程介绍的时候尽量苦口婆心,絮絮叨叨讲一大堆,在实操的时候我们就要变得干脆利索起来。今天的...

由左左在2019年6月1日上张贴今天,我们来做一个简单的教程,介绍下如何开启GoogleConsole首先,我们先看看维基百科上是怎样介绍GoogleConsole的:Console是Google开发的一个面向网站管理员的免费工具。网站管理员可以通过该工具了解自己网站的收录情况并优化其网站的曝光率。功能谷歌网站管理员工具可以做到以下几个方面:提交...

现在几乎所有做外贸电商独立网站的人都知道可信度的重要性。可信度包含很多方面的内容,今天这个教程我们就只讨论SSL证书和信托密封什么是SSL证书?说简单点就是网址可以由http变成https那什么是信托密封?就是一个类似于这样子的图标,通常点击以后会弹出一个窗口,到他们的官方网站看到认证信息如果是做外贸电商,我认为最好是选择国外比较有名的SSL证书,尽量避免免...
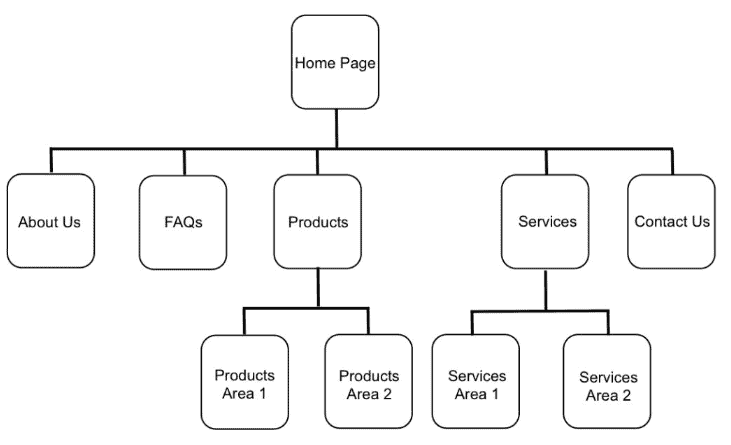
你有没有碰到过这种情况:有的网站,打开半天都不知道自己想要的东西在哪里,不得不求助于搜索栏(如果搜索不到,就更懊恼了)。有的网站,点击几下鼠标就可以很轻易的找到自己想要的东西了,你的体验会很愉悦。为什么会出现这种问题?这是因为他们使用了不同的网站结构。那什么是网站结构?网站的结构是指网页的组织方式,即各个子页面如何相互关联,它展示了站长在逻辑上如何分组信息,...