谷歌搜索引擎索引的工作原理
作者:zuozuo | 分类:谷歌SEO | 浏览:142 | 日期:2022年10月24日在昨天的《谷歌SEO入门系统培训课程大纲》中,左左为初学者列出了的基本的知识框架。外贸独立站如何选择域名,我们已经在这一篇教程中详细介绍过。我们也曾经在另外一篇教程中介绍过如何用几分钟搭建自己的第一个WordPress网站。第三节谷歌的使命,我们可以从官方网站得知,这里就不重复介绍。今天我们就来讲讲最重要的一个部分——谷歌的工作原理。
我们以前曾经发布过一篇《谷歌工作原理概述》,网友反映太简单了,希望我仔细讲解一下。那我们就多花点篇幅,争取把这个话题讲透。
左左学堂的SEO课程基本上都很重视讲原理,用时髦的说法就是重视讲底层逻辑。我一直认为谷歌的工作原理是每一个学习谷歌SEO的人应该了解的第一堂课。很多人学习SEO是从站内优化开始的,另外一些人是从外链建设开始的,可是你们知道为什么要做站内优化吗?你知道为什么有些站内优化手法有用,另外一些是Bullshit吗?你的判断依据从何而来?经验能够在一定程度上帮助你,可是万一你的经验过时了呢?有没有更加Reliable的方法?我认为如果你能够在事先多了解一下谷歌的工作原理,那么你的判断将会更加可靠。
如何判断各种SEO技术的可靠性?
左左现在学习各种SEO技术之前,都会事先判断一下它的潜在价值和风险。我有两条原则:第一、它有助于我配合谷歌完成自己的使命吗?第二、它符合谷歌的工作原理吗?只要有违背任何一条原则,我都会弃之不用。不管传播SEO知识的那个人是什么大咖,包装得有多闪亮,听起来多么诱人,我都会敬而远之。这是我的个人经验,仅供大家参考。
谷歌为什么那么重视左侧自然排名结果的准确性?
这个问题大概很少人会去思考。我们现在讲谷歌优化技术,一般而言都是指优化左侧的自然排名,英文中叫做Organic search result(响应网友的需要,左左会提高谷歌SEO专有名词的使用频率)。但是在深入讲这个之前,我们想花一点时间讨论一件核心的事实。
请自己站在谷歌的立场来思考一个问题:左侧的自然排名对于谷歌来说,或者对任何其他搜索引擎来说,能给他们公司带来收入吗?答案当然是否定的。不管有多少人点击自然排名的结果,对于谷歌来说,直接的收入都是零。那么它为什么费那么多心思,花费那么多人力物力和财力去不断优化算法公式,来为用户提供更有价值的内容呢?国外SEO业界对这个问题展开过深入讨论,他们认为谷歌的自然排名结果只是达成目的的手段,而他们的目的也很简单,那就是为了产生利润。谷歌的自然搜索结果能够展示他们在匹配用户意图方面的能力,只要你使用过谷歌搜索,你肯定曾经为结果页面的准确性而感到惊艳。它们和你的搜索意图如此相关,你不得不对谷歌感觉心悦诚服。如果你是一个商家,你还会怀疑他们付费广告的可靠性吗?所以说,如果不是谷歌的自然搜索结果那么优秀,商家不会那么信任付费搜索的效果。那么谷歌就没办法吸引那么多广告商家的眼球,愿意为之付费的人自然就少了。谷歌和其他的搜索引擎一样,绝大多数的利润都来自于付费广告收入。他们为了吸引更多用户购买广告,就必然会千方百计使自然搜索的结果更加匹配用户意图,搜索结果越准确,使用谷歌的人就会越多,点击广告的人自然也会越多。所以说,搜索引擎的自然搜索结果是它们达成目的的手段,而不是目的本身。
左左为什么要先把这个问题放出来着重介绍一下,就是为了让我们能够从更深的角度去体会谷歌的意图,甚至预测发展方向。这些年谷歌自然搜索结果页面的样式经历过许多变迁,我们见证了知识面板(knowledge panel)和精选片段(featured snippet)的诞生,也知道谷歌现在把点击率(click-through rates)当成算法排名的重要因素。点击率,对于付费广告来说是多么重要的事情啊,现在都计入自然排名算法里面了。大家不妨想想看,谷歌以后会有一些什么变化,来帮助他们更好地实现自己的最终目的呢?
现在,我们言归正传,继续讨论谷歌排名的工作原理。这个话题比较大,我们今天就来讲第一个方面——谷歌爬虫和索引。
谷歌爬虫和索引的基础知识
谷歌爬虫(crawler),也叫谷歌蜘蛛(spider),是谷歌开发出来的自动浏览网页的机器人程序(bot),其目的就是为了编纂索引。需要请大家记住的是,爬虫、蜘蛛和机器人都是一个东西。
索引(Indexing),也叫收录,是谷歌排名开始工作的起点。通俗来说,索引就是把我们网站的内容添加到谷歌的数据库之中。怎么添加呢?就是靠蜘蛛来抓取。(讲到这里,你应该就不难明白,做SEO一定不要屏蔽谷歌机器人。左左以前就看到过有建站公司给人搞的外贸网站,不允许谷歌机器人访问的,神奇吧?就是这么神奇。)
当我们网站新建立了一个页面,有哪些方式让谷歌索引它?
最简单的方式是啥都不要干,让谷歌自己去发现新页面。谷歌的爬虫会沿着网站的链接到处访问网站页面,就像是蜘蛛会沿着蛛网爬一样。链接就像是蜘蛛丝,这也是spider这一名称的由来。但是这样做有2个前提条件:
你的网站已经被谷歌索引过;在已经索引过的网页中包含有指向新网页的链接;
(讲到这里,你们应该可以更好地理解《深度解析网站结构 (Web Structure)》这篇教程背后的原理了吧?如果没读过,我建议大家认真读看看。)
坐着不动是一种最简单的办法,但是有时候我们也会希望谷歌可以更快地收录我们的网页。比如说你发布了一些最新的消息,或者是更正了网页上某些重要内容,你希望谷歌能够尽快更新数据,这样潜在的用户能够看到你希望展示的搜索结果。就左左个人来讲,我会时不时地检查下元描述标签,修改下措辞,看能不能够吸引更多的用户点击。如果我修改了这些东西,我就会主动提交给谷歌搜索引擎。如何让google收录网页呢?我们可以通过两种方式达成此目的。
主动提交搜索引擎索引的方法:用Google Search Console 工具提交XML地图
Google Search Console原来叫做Google Webmaster Tool,是谷歌站长管理员工具。XML地图包含两类重要的信息,第一类是网址列表,告诉谷歌你们网站上有哪些网页;第二类是最后修改时间,告诉谷歌有哪些网页内容出现了变动。谷歌的蜘蛛程序根据XML地图判断,有哪些新的页面生成,或者有哪些页面需要重新索引。
对于一个外贸独立站来说,你的网站系统必须要能够生成并且随时更新XML地图。这样谷歌才会及时更新你们网站的内容。如果你使用的是WordPress系统,我们可以使用Yoast插件来实现这个功能。XML地图是新站快速收录的利器。
直接到Search Console中提交网址
登录自己的Google Search Console,在顶部的搜索框输入新网址
然后回车键,就这么简单。
如果你的网址已经被收录了,你会看到如下内容:
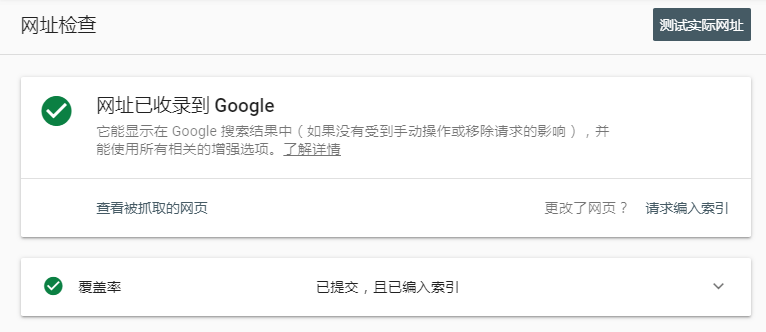 谷歌收录情况
谷歌收录情况
如果你的网页内容有所变更,你可以点击下“请求编入索引”链接。Google会重新检查网页内容。
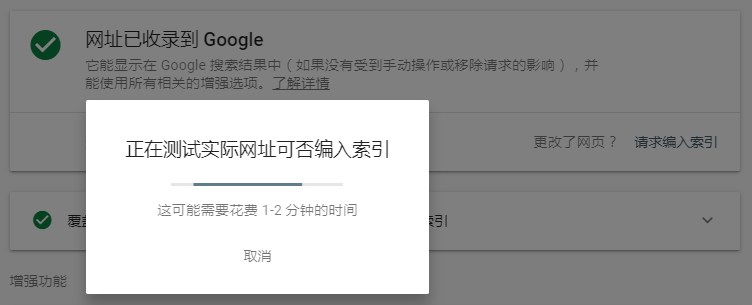 请Google更新索引内容
请Google更新索引内容
不管是提交新网址,还是更新了网站内容,谷歌索引的时间只要一两分钟,有时候几秒就可以收录了。需要注意的是,我们尽量避免重复提交同一个网址,只需要提交一次即可。
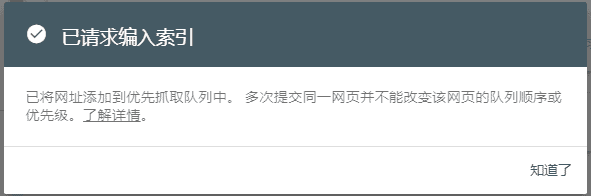
切记多次重复提交谷歌索引
Search Console是谷歌的站长工具,雅虎和Bing都有类似的工具。大家不妨搜索“Yahoo Webmaster Tool”和“Bing Webmaster Tools ”自己去尝试下提交XML地图或者单独的网址。
有关谷歌索引的知识,讲到这里就基本上可以告一个段落了。 如果你只是运营一个规模不大的外贸独立站,掌握这些知识和技巧就够用了。
如果你的网站规模较大,每天有很多新的网页等待谷歌索引,那么你也许听到过抓取预算这个词。
抓取预算是中文翻译,英文中的说法是Crawl Budget。 抓取预算是一个术语,用于描述Google抓取网站将花费的资源量。通俗的说,谷歌蜘蛛多久访问一次你的网站,每一次访问会持续多长时间。
Crawl Budget取决于很多因素,最核心的两点因素是网站服务器速度和网站的重要程度。
如果你的网站服务器性能优良,谷歌蜘蛛多访问一下,不至于拖慢网页的加载速度,影响用户的体验。(这下你明白网站加载速度为什么会成为谷歌排名算法的核心考量了吧?)
如果你的网站频繁更新用户希望看到的重要内容,谷歌蜘蛛也会访问更加频繁。 这里需要注意的是,网站更新的内容必须是用户喜欢看到的东西。(这下你明白为什么用户停留时间和重复访问次数也会成为谷歌排名算法的核心因素了吧)。
抓取预算就是这么个概念,没有什么神秘的。现在网上有些SEO博客过于夸大这个概念的普适性和神秘性,让大家学习如何去优化抓取预算(而且提出的建议乱七八糟),搞得大家以为SEO是多么难学的东西。
对于外贸独立站来说,你们网站上的内容就那么多,只要谷歌能够及时索引就可以了。如果你要运营一个相当大规模的外贸网站,或者想做职业的SEO,你可以访问谷歌官方博客了解有关抓取预算的更多内容,不过这就已经超出我们为小白SEO准备的课程范围了。
今天的课程就到这里,左左在这篇教程中采用了串讲的模式,用()联系起其他的知识点,试图帮助大家建立思维框架。但这毕竟是一篇基础教程,考虑到主要是为小白讲的,我们就没有讲怎么在自己网站中生成xml地图并提交谷歌搜索引擎了。大家不要着急,等我们以后讲站内SEO的时候,会详细介绍具体的实现步骤的。


